Candicetan

Credit analyst with extensive experience in risk analysis and recommending for various lending proposals.
Machine learning and advanced analytics with Python
Project description: A data analyst is tasked to perform loan analysis and to build Machine learning models to present to the Credit risk management of the bank with the insights on how to minimise default risk for small-medium enterpriseses under Commercial Banking.

1. Data collection
Research from Kaggle: https://www.kaggle.com/mirbektoktogaraev/should-this-loan-be-approved-or-denied
2. Exploratory Data Analysis (EDA), feature engineering and data preprocessing
- Explore and observe the relationships using statistical methods
- Remove records from columns with null values.
- Correct each field to the appropriate data type(currency fields that are being read as objects rather than floats, “ApprovalFY” have a mixture of integers and strings.
- Address industry codes- use the first 2 digits of each business’s industry code to map to the corresponding industries to use this as a reference.
- Perform feature engineering, i.e. create and derive new measurement that would add-value to the analysis, i.e, SBA_guarantee%, loan status, industry code etc.
- To account for the % of SBA loan guaranteed. This is the unique feature SBA loans have where the SBA will ‘guaranty’ a percentage of the loan in the event of a loss, loans are typically guaranteed on a percentage basis rather than a specified dollar amount;
- Create a flag that signifies if the loan term is >= 20 years, as real estate-backed loans are typically at least this long and loan term is usually tied to the useful life of the collateral.
- Clean the fields that won’t provide much value to the analysis- city, zip, bank name etc

3. Data analysis and visualization
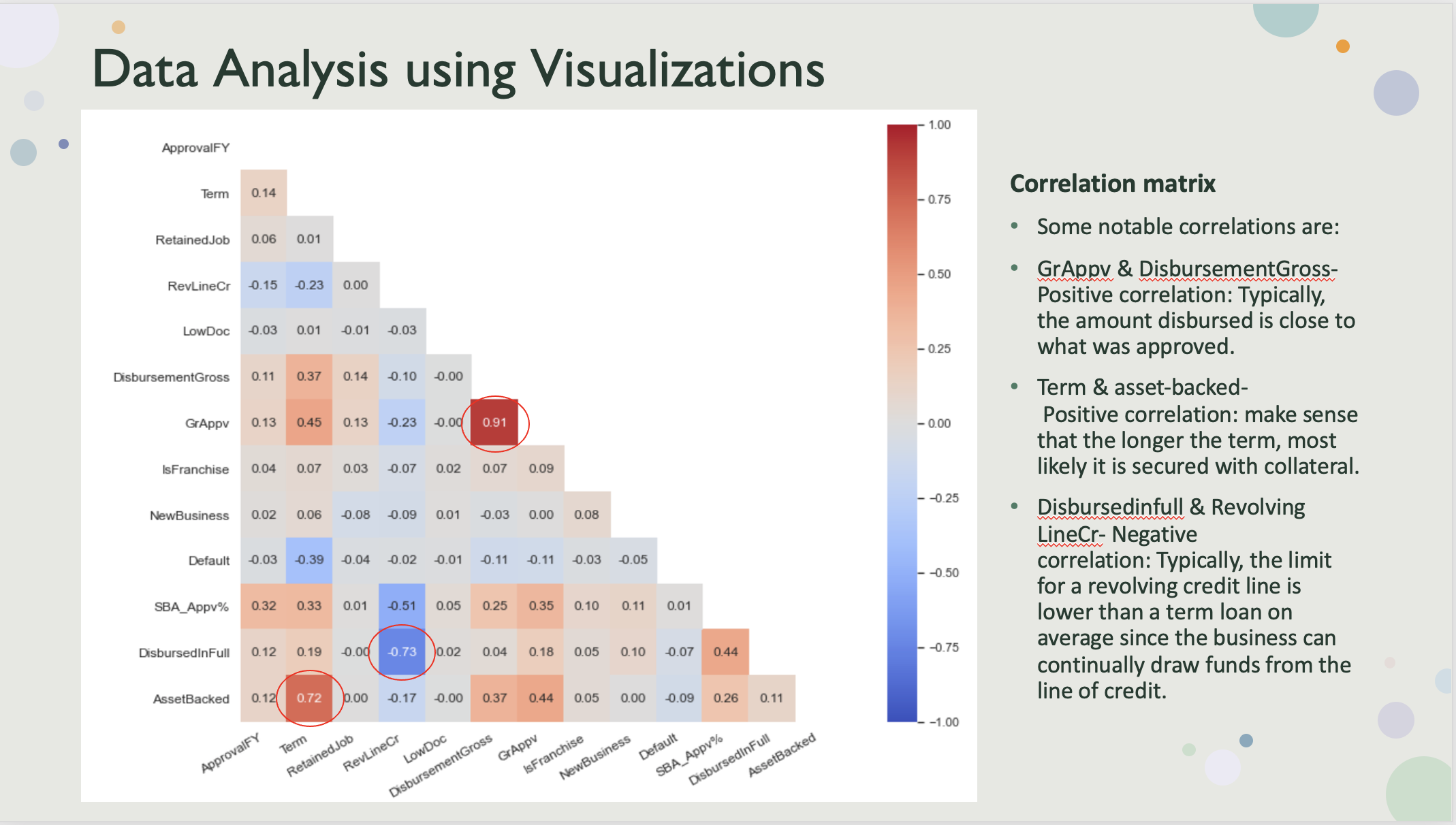
Correlation matrix created to visualize the relationship among the features and some notable correlations.
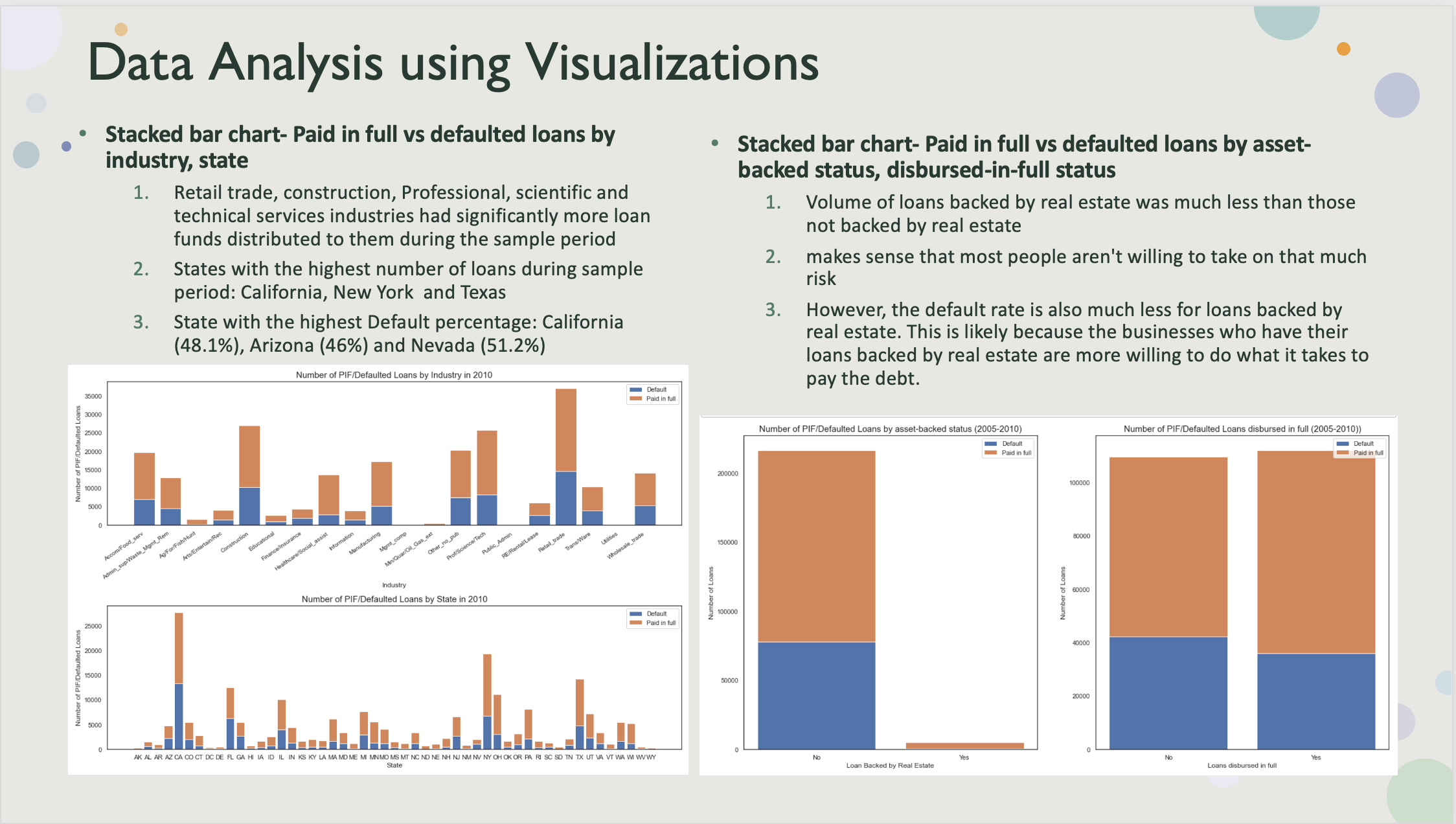
Visualisation for paid in full status vs defaulted loans by industry, state, asset-backed status, disbursed-in-full status.
4. Machine learning model evaluation and recommendations
Modeling with Logistic regression, Random forest, Multi level perceptron (classification problem).
To keep in mind when evaluating model performance that a good accuracy doesn’t necessarily mean the model performed well. We want to consider metrics like precision, recall, and F1-score (weighted average of precision and recall) to ensure we are evaluating model performance based on the ‘cost’ of the outcomes.
Baseline model Logistic regression yields a decent accuracy at 83%, however the F1-score of 75% for defaulted loans does not appear to be very promising. The precision suggests that the model is correct 80% of the time when the loan defaults. Recall suggests that the model identifies 70% of defaulted loans correctly, which means that 30% of loans that defaulted were incorrectly classified as loans that would be fully paid, which could provide misleading outcome.
Random forest model performs better across the board with a general accuracy of 93% and higher precision, recall and F1-score.
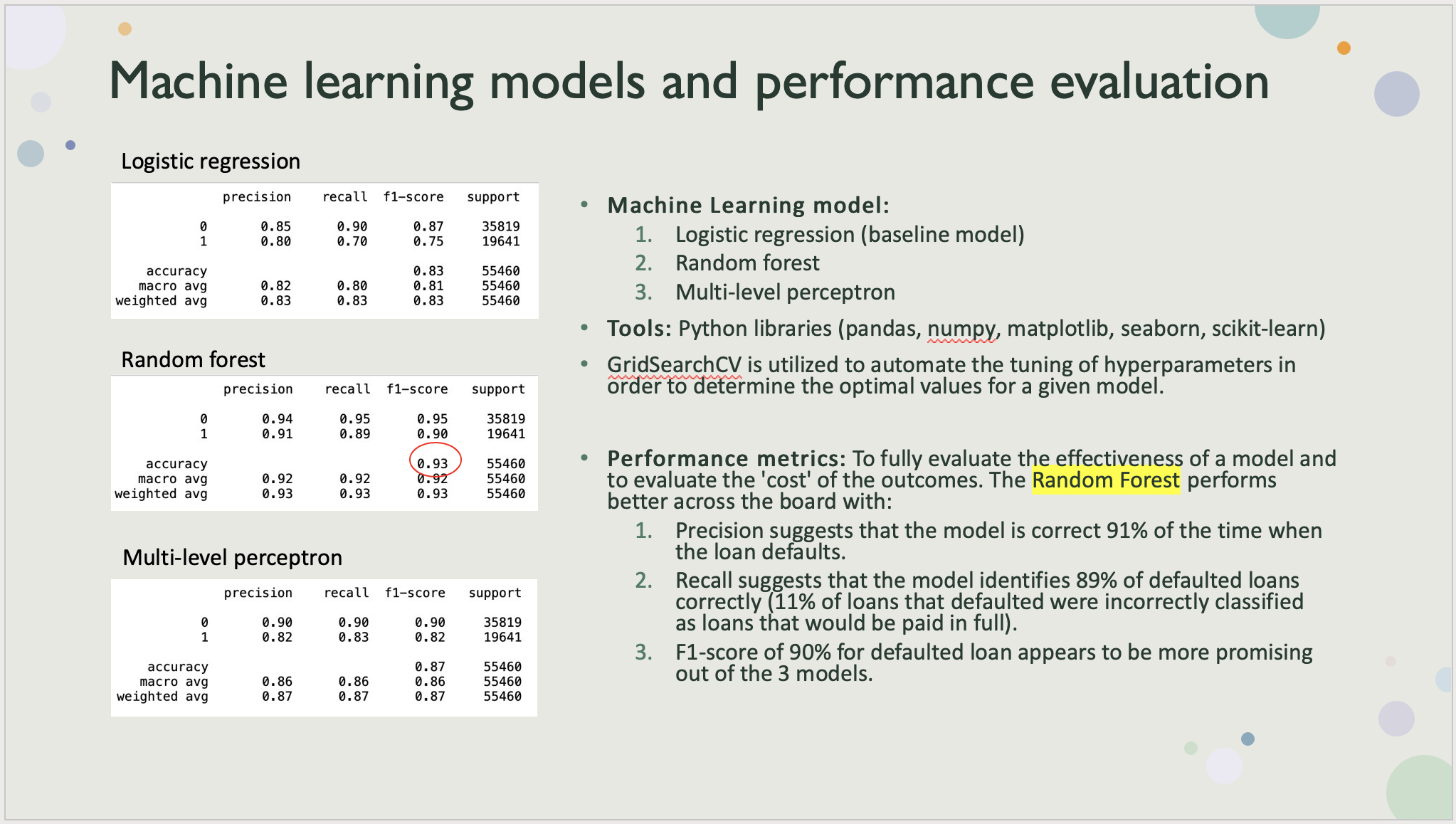
In general, a model that outperforms another model on both precision and recall is likely the better model.
In this scenario general accuracy and f1-score could be relied on when the outcomes have similar costs.
